Quant Models We can use them and remove limitations
Aggregation limits speed & accuracy
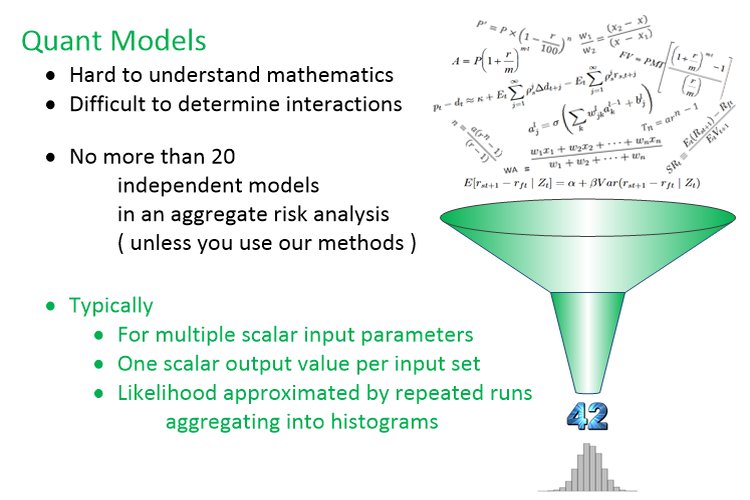
Quant models limit analysis
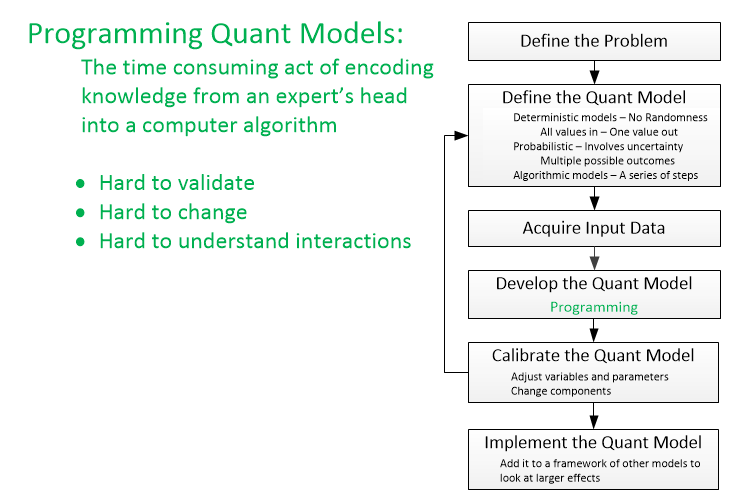
How they work:
- Typically - Scalar inputs & scalar outputs
- Multiple scalar input parameters
- One scalar output value per input set
- Variations in inputs used to simulate likelihood - allow for Sensitivity Analysis and Uncertainty Analysis
- Likelihood approximated by repeated runs aggregating into histograms
- Sometimes the histogram is then fit to a statistical measure - like mean and std. deviation.
How they fail:
- Hard to understand mathematics
- Hard to calibrate, adapt, & change
- Difficult to determine interactions between factors
- No Drill-down - Insight lost to Complexity
- Aggregating methods limited to less than 20 independent sources of risk (less than 20 independent Quant models).
We can use your Quant models. Where the rules are understood, they are especially useful. Where the rules are not understood, we have other methods to capture expert knowledge.
We increase speed and complexity where current aggregating methods are limited.
Our strength is in faster and more accurate methods that get around the
20 independent Risk model limit built into any system that aggregates scalar
models into histograms.
There are no lack of Patents trying to get around that limit. De Prisco
et al. (US Pat. No. 7,908,197) is one example. They explain typical systems
fairly well, and reference many other patents. What they are not telling
you is that they don't get around the problem. For their neural-net method
to work, their incoming models must be interdependent.
We can solve systems containing thousands of independent sources of Risk - more than any other Patented system.
Compared to any Monte-Carlo based risk analysis methods, we're
- Faster - orders of magnitude Faster
- More Accurate - We're numerically more accurate on every probability distribution
- Complexity - We can handle much more complexity.
We work with bounded asymetric probability distributions.
Think about it... on any investment, is your upside risk always equal
to your downside risk?
Yet, every time an analyst cites a mean and standard deviation - that's
what they are saying.
We work with probability distributions at points in time, and calculate over distributions - rather than aggregating single point solutons like Monte-Carlo based methods.
We have a simple paradigm - Bars on a Gantt-like chart. With each Bar representing a different risk factor varying in time, and the ability to handle thousands of independent risk factors - our methods are capable of handling much more complicated scenarios than any other time dependent risk analysis system - no other analysis system described in US Patents even comes close.
Your quant models - Our aggregating methods
Reuse your quant models - with more speed and accuracy
Financial modelling is about translating a set of hypotheses about the
behavior of markets or agents into numerical predictions.
See:
Building typical financial models entails genrating complicated numerical models - usualy by having programers (who know little about the problem) work with domain experts (who know little about programming) - working back and forth - validating - till they get a model for that aspect of the problem right. Then, they use a different numerical method to aggregate different models.
Although almost everybody does it this way, no one ever said you had to do it one point at a time ( Patents pending).
We take a different approach:
- Build your models about each aspect of the risk analysis independently.
- If they couple, run them together. If they do not, run them separately.
- Use the models to calculate probability distributions at points in time - for each model or coupled collection of models.
- Use our Patents pending methods to aggregate the model results.
IF you are currently using any Monte-Carlo based modeling - or any method that aggregates scalar values into histograms to predict likelihood - you are limited to less than 20 truly independent sources of risk.
Using our methods - depending on the server we're running on - we
should be able to aggregate thousands of your models quickly.
On a quad core laptop - 400 models/minute. On our small (24 core) server,
we expect 130,000 models/hour.
Our methods scale linearly, and parallelize well. If you need a bigger
server - call us.
Speed changes everything.